A digitális adatok mennyisége rohamos ütemben nő. Nem meglepő, hogy a szervezetek első számú teendői között szerepel, hogy kezeljék ezt az információtömeget. Az adatok deduplikációja továbbra is a legfontosabb és leggyorsabban növekvő tárolásoptimalizálási technikák közé tartozik, amely segít a kihívás leküzdésében.
A deduplikációs folyamat során a duplikált adatok törlődnek, így csupán egy példányt kell belőlük tárolni. A törölt adatok indexelése azonban továbbra is megmarad arra az esetre, ha szükség lenne rá, és vissza is lehet őket állítani. A törlés és indexelés eredményként a deduplikáció viszont csökkenti a szükséges tárolókapacitást.
Intelligens másolatcsere
Az adatok deduplikációjáról gondoskodó technológia összehasonlítja az információdarabokat, és minden egyedi adatszegmenst csak egyszer tárol. A deduplikációs motor minden egyes ilyen adatblokkhoz egyedi azonosítót rendel matematikai hash függvények segítségével. Ha két blokkot azonosnak talált a rendszer, akkor a másolatot lecseréli az eredeti darabra mutató hivatkozással.
Ezzel jelentős mennyiségű tárhelyet lehet megspórolni különösen az olyan, sok redundáns adatot tartalmazó területek esetében, mint az adatbázisok. A deduplikáció azonban nem oldja meg egyből a tárhelyproblémákat, időbe telik ugyanis, míg megfelelő eredményeket érnek el vele. Ezért először mindenképpen a meglévő biztonsági mentési stratégiához és a várható adatmennyiség-növekedéshez érdemes méretezni a tárhely mennyiségét.
A későbbiekben azonban valóban több adatot képesek tárolni a vállalatok ezzel a módszerrel. Továbbá a katasztrófa utáni helyreállítás során az RPO (recovery point objective) értékeik is javulnak, mivel a korábbiakhoz képest régebbi mentésekből is visszaállíthatók azok az adatok, amelyeket hosszabb ideje tárolnak.
A deduplikáció emellett alacsonyabb költséggel teszi lehetővé a helyek közötti replikációt egy katasztrófa utáni helyreállítás során. Mivel a deduplikációs technológia követi, hogy blokk- vagy bájtszinten milyen adatok változtak, ezért a replikáció intelligensebbé válik, és csak a megváltozott adatokat továbbítja, nem a teljes adatkészletet. Ezáltal időt és replikációs sávszélességet takarít meg, ami az egyik legfontosabb pozitívum a deduplikációban a vállalatok számára.
Data Protector: új köntösben, megújult tartalommal
A Micro Focus portfóliójába tartozó Data Protector már több mint tíz éve jelentkezett először deduplikációs képességekkel, ám a nemrégiben megjelent 11.0 változat teljes egészében megújult deduplikációs motort tartalmaz, amely jelentős mértékben kibővíti a megoldás funkcióit. Több különféle új tárolási platformmal képes együttműködni, és a deduplikációs képesség többféle adathordozón is alkalmazható fizikai, virtuális és felhőkörnyezetben egyaránt, az adatközpontban vagy távoli helyszeneken is.
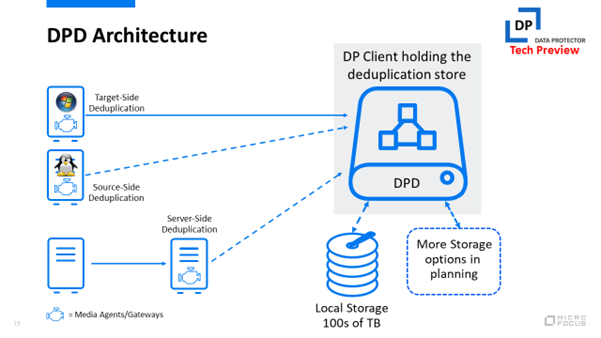
A megoldás támogatja a Windows és a Linux rendszereket a forrás- és a céloldali deduplikációban is, és a Microsoft 365 Exchange Online biztonsági mentési funkciójában is történtek további fejlesztések, tekintettel az online alkalmazások növekvő népszerűségére. Az eszköz teljes vagy inkrementális biztonsági mentésre is lehetőséget nyújt, illetve postafiók- és mappaszinten is lehet visszaállítást végezni vele, ami felgyorsítja a folyamatot, és kevesebbet használ a kapacitásból. A biztonsági mentési adathordozó pedig bárhova másolható, ami növeli a biztonságot és a rendelkezésre állást is.
A Data Protector így vállalati szintű biztonsági másolatkészítést és katasztrófa utáni helyreállítást, valamint teljes körű backup képességeket kínál a teljes vállalati környezetben. Képes védelmet nyújtani a heterogén, földrajzilag elosztott helyen található adatközpontokban, fiókirodákban és üzlethelyiségekben, illetve többfelhős környezetekben. A központi IT részleg ezáltal átfogó védelmet és katasztrófa utáni helyreállítást biztosíthat, miközben csökkenti tudja az adatvesztés okozta alkalmazás- és szolgáltatáskimaradásokat vagy leállásokat. Ennek köszönhetően a szervezetek könnyebben teljesíthetik a biztonsági, megfelelőségi és felügyeleti követelményeket.